About
The recent popularity of big data has brought immense quantities of high-dimensional data, which presents challenges to traditional data mining tasks due to curse of dimensionality. Feature selection has shown to be effective to prepare these high dimensional data for a variety of learning tasks. To provide easy access to feature selection algorithms, we provide an interactive feature selection tool FeatureMiner based on our recently released feature selection repository scikit-feature. FeatureMiner eases the process of performing feature selection for practitioners by providing an interactive user interface. Meanwhile, it also gives users some practical guidance in finding a suitable feature selection algorithm among many given a specific dataset. In this demonstration, we show (1) How to conduct data preprocessing after loading a dataset; (2) How to apply feature selection algorithms; (3) How to choose a suitable algorithm by visualized performance evaluation.
Tutorial
Steps:
-
After you download feature_miner.zip, unzip the archive. Then the feature_miner root directory will contain two folds build and dist.
-
Go to fold dist, run the feature miner.exe, without installation you can use Feature Miner tool directly.
Matters needing attention
Due to efficiency of algorithm, some methods belong to the following categories need relative long time to process. Please be patient.
-
information theoretic based
-
wrapper
-
sparse learning based
Additional Views of FeatureMiner
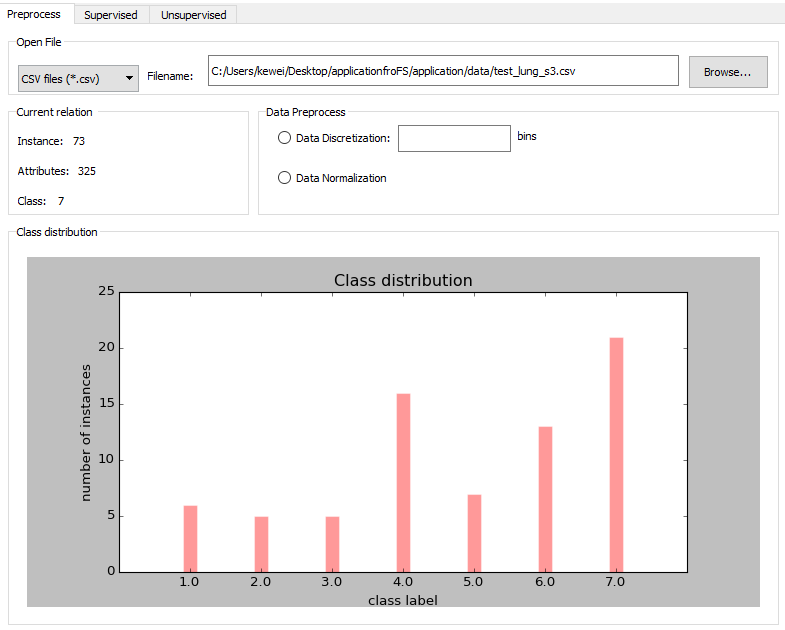
Preprocess Tab
The preprocess tab of FeatureMiner showing example of loading lung cancer dataset.
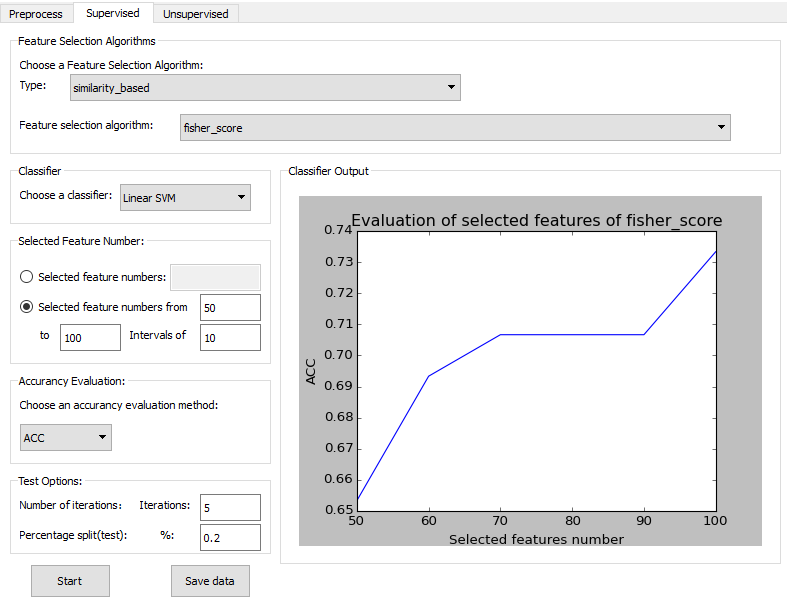
Supervised Tab
The supervised tab of FeatureMiner showing example of conducting fisher score algorithm.
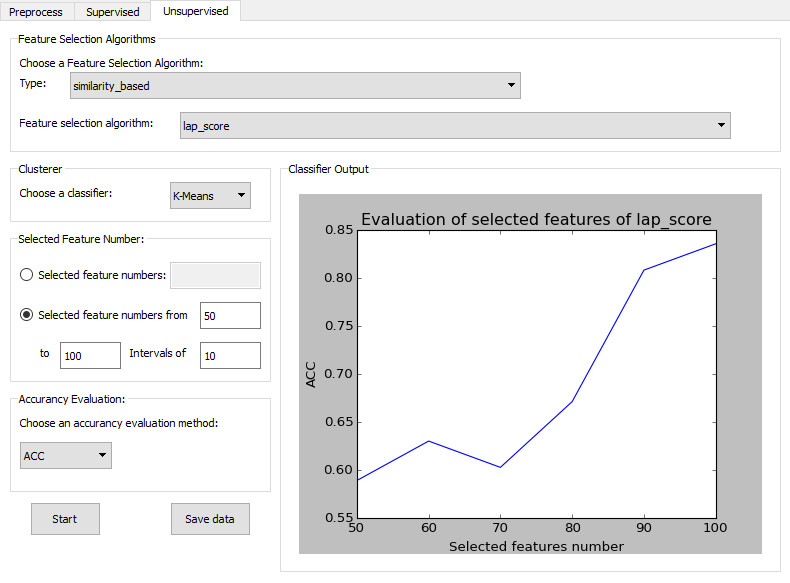
Unsupervised Tab
The unsupervised tab of FeatureMiner showing example of conducting laplacian score algorithm.
Data sets
To download some feature selection data sets, please click here.